Apache Hive
|
| |
| Developer(s) | Contributors |
|---|---|
| Stable release |
2.0.0[1]
/ February 15, 2016 |
| Development status | Active |
| Written in | Java |
| Operating system | Cross-platform |
| Type | Data warehouse |
| License | Apache License 2.0 |
| Website |
hive |
Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis.[2] Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop. The traditional SQL queries must be implemented in the MapReduce Java API to execute SQL applications and queries over a distributed data. Hive provides the necessary SQL abstraction to integrate SQL-like Queries (HiveQL) into the underlying Java API without the need to implement queries in the low-level Java API. Since most of the data warehousing application work with SQL based querying language, Hive supports easy portability of SQL-based application to Hadoop.[3] While initially developed by Facebook, Apache Hive is now used and developed by other companies such as Netflix and the Financial Industry Regulatory Authority (FINRA).[4][5] Amazon maintains a software fork of Apache Hive that is included in Amazon Elastic MapReduce on Amazon Web Services.[6]
Features
Apache Hive supports analysis of large datasets stored in Hadoop's HDFS and compatible file systems such as Amazon S3 filesystem. It provides an SQL-like language called HiveQL[7] with schema on read and transparently converts queries to MapReduce, Apache Tez[8] and Spark jobs. All three execution engines can run in Hadoop YARN. To accelerate queries, it provides indexes, including bitmap indexes.[9] Other features of Hive include:
- Indexing to provide acceleration, index type including compaction and Bitmap index as of 0.10, more index types are planned.
- Different storage types such as plain text, RCFile, HBase, ORC, and others.
- Metadata storage in an RDBMS, significantly reducing the time to perform semantic checks during query execution.
- Operating on compressed data stored into the Hadoop ecosystem using algorithms including DEFLATE, BWT, snappy, etc.
- Built-in user defined functions (UDFs) to manipulate dates, strings, and other data-mining tools. Hive supports extending the UDF set to handle use-cases not supported by built-in functions.
- SQL-like queries (HiveQL), which are implicitly converted into MapReduce or Tez, or Spark jobs.
By default, Hive stores metadata in an embedded Apache Derby database, and other client/server databases like MySQL can optionally be used.[10]
Four file formats are supported in Hive, which are TEXTFILE,[11] SEQUENCEFILE, ORC[12] and RCFILE.[13][14][15] Apache Parquet can be read via plugin in versions later than 0.10 and natively starting at 0.13.[16][17] Additional Hive plugins support querying of the Bitcoin Blockchain.[18]
Architecture
Major components of the Hive architecture are:
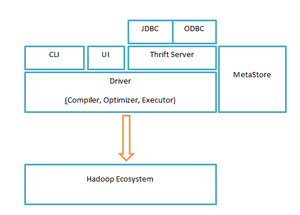
- Metastore: Stores metadata for each of the tables such as their schema and location. It also includes the partition metadata which helps the driver to track the progress of various data sets distributed over the cluster.[20] The data is stored in a traditional RDBMS format. The metadata helps the driver to keep a track of the data and it is highly crucial. Hence, a backup server regularly replicates the data which can be retrieved in case of data loss.
- Driver: Acts like a controller which receives the HiveQL statements. It starts the execution of statement by creating sessions and monitors the life cycle and progress of the execution. It stores the necessary metadata generated during the execution of an HiveQL statement. The driver also acts as a collection point of data or query result obtained after the Reduce operation.[14]
- Compiler: Performs compilation of the HiveQL query, which converts the query to an execution plan. This plan contains the tasks and steps needed to be performed by the Hadoop MapReduce to get the output as translated by the query. The compiler converts the query to an Abstract syntax tree (AST). After checking for compatibility and compile time errors, it converts the AST to a directed acyclic graph (DAG).[21] DAG divides operators to MapReduce stages and tasks based on the input query and data.[20]
- Optimizer: Performs various transformations on the execution plan to get an optimized DAG. Various transformations can be aggregated together, such as converting a pipeline of joins by a single join, for better performance.[22] It can also split the tasks, such as applying a transformation on data before a reduce operation, to provide better performance and scalability. However, the logic of transformation used for optimization used can be modified or pipelined using another optimizer.[14]
- Executor: After compilation and Optimization, the Executor executes the tasks according to the DAG. It interacts with the job tracker of Hadoop to schedule tasks to be run. It takes care of pipelining the tasks by making sure that a task with dependency gets executed only if all other prerequisites are run.[22]
- CLI, UI, and Thrift Server: Command Line Interface and UI (User Interface) allow an external user to interact with Hive by submitting queries, instructions and monitoring the process status. Thrift server allows external clients to interact with Hive just like how JDBC/ODBC servers do.[23]
HiveQL
While based on SQL, HiveQL does not strictly follow the full SQL-92 standard. HiveQL offers extensions not in SQL, including multitable inserts and create table as select, but only offers basic support for indexes. Also, HiveQL lacks support for transactions and materialized views, and only limited subquery support.[24][25] Support for insert, update, and delete with full ACID functionality was made available with release 0.14.[26]
Internally, a compiler translates HiveQL statements into a directed acyclic graph of MapReduce, Tez, or Spark jobs, which are submitted to Hadoop for execution.[27]
Example
"Word count" program
The word count program counts the number of times each word occurs in the input. The word count can be written in HiveQL as:[3]
1 DROP TABLE IF EXISTS docs;
2 CREATE TABLE docs (line STRING);
3 LOAD DATA INPATH 'input_file' OVERWRITE INTO TABLE docs;
4 CREATE TABLE word_counts AS
5 SELECT word, count(1) AS count FROM
6 (SELECT explode(split(line, '\s')) AS word FROM docs) temp
7 GROUP BY word
8 ORDER BY word;
A brief explanation of each of the statements is as follows:
1 DROP TABLE IF EXISTS docs;
2 CREATE TABLE docs (line STRING);
Checks if table docs exists and drops it if it does. Creates a new table called docs with a single column of type STRING called line.
3 LOAD DATA INPATH 'input_file' OVERWRITE INTO TABLE docs;
Loads the specified file or directory (In this case “input_file”) into the table. OVERWRITE specifies that the target table to which the data is being loaded into is to be re-written; Otherwise the data would be appended.
4 CREATE TABLE word_counts AS
5 SELECT word, count(1) AS count FROM
6 (SELECT explode(split(line, '\s')) AS word FROM docs) temp
7 GROUP BY word
8 ORDER BY word;
The query CREATE TABLE word_counts AS SELECT word, count(1) AS count creates a table called word_counts with two columns: word and count. This query draws its input from the inner query (SELECT explode(split(line, '\s')) AS word FROM docs) temp". This query serves to split the input words into different rows of a temporary table aliased as temp. The GROUP BY WORD groups the results based on their keys. This results in the count column holding the number of occurrences for each word of the word column. The ORDER BY WORDS sorts the words alphabetically.
Comparison with traditional databases
The storage and querying operations of Hive closely resemble with that of traditional databases. While Hive works on an SQL-dialect, there are a lot of differences in structure and working of Hive in comparison to relational databases. The differences are mainly because Hive is built on top of Hadoop ecosystem and has to comply with the restrictions of Hadoop and MapReduce.
Schema is applied to a table in traditional databases. However, the table enforces the schema at the time of loading the data. This enables the database to make sure that the data entered follows the representation of the table as specified by the user. This design is called schema on write. Hive, when it saves its data into the tables, does not verify it against the table schema during load time. Instead, it follows a run time check. This model is called schema on read.[24] The two approaches have their own advantages and drawbacks. Checking data against table schema during the load time adds extra overhead which is why traditional databases take a longer time to load data. Quality check is performed against the data at the load time to ensure that the data is not corrupt. Early detection of corrupt data ensures early exception handling. Since the tables have schema ready after the data load, it has better query time performance. Hive, on the other hand, can load data dynamically without any schema check, ensuring a fast initial load but displays comparatively slower performance at query time. Hive does have an advantage when the schema is not available at the load time, instead is generated later dynamically.[24]
Transactions are key operations in traditional databases. A typical RDBMS supports all 4 properties of Transactions (ACID): Atomicity, Consistency, Isolation, and Durability. Transactions in Hive were introduced in Hive 0.13 but were only limited to partition level.[28] Only in the recent version of Hive 0.14 were these functions fully added to support complete ACID properties. This is because Hadoop does not support row level updates over specific partitions. These partitioned data are immutable and a new table with updated values has to be created. Hive 0.14 and later provides different row level transactions such as INSERT, DELETE and UPDATE.[29] Enabling INSERT, UPDATE, DELETE transactions require setting appropriate values for configuration properties such as hive.support.concurrency, hive.enforce.bucketing, and hive.exec.dynamic.partition.mode.[30]
Security
Hive v0.7.0 added integration with Hadoop security. Hadoop has begun using Kerberos authorization support to provide security. Kerberos allows for mutual authentication between client and server. In this system, the client’s request for a ticket is passed along with the request. The previous versions of Hadoop had several issues such as users being able to spoof their username by setting the hadoop.job.ugi property and also MapReduce operations being run under the same user: hadoop or mapred. With Hive v0.7.0’s integration with Hadoop security, these issues have largely been fixed. TaskTracker jobs are run by the user who launched it and the username can no longer be spoofed by setting the hadoop.job.ugi property. Permissions for newly created files in Hive are dictated by the HDFS. The HDFS (Hadoop distributed file system) is similar to the Unix file system, where there are three entities: user, group and others with three permissions: read, write and execute. The default permissions for newly created files can be set by changing the umask value for the Hive configuration variable hive.files.umask.value.[3]
See also
References
- ↑ "Apache Hive Download News".
- ↑ Venner, Jason (2009). Pro Hadoop. Apress. ISBN 978-1-4302-1942-2.
- 1 2 3 Programming Hive [Book].
- ↑ Use Case Study of Hive/Hadoop
- ↑ OSCON Data 2011, Adrian Cockcroft, "Data Flow at Netflix" on YouTube
- ↑ Amazon Elastic MapReduce Developer Guide
- ↑ HiveQL Language Manual
- ↑ Apache Tez
- ↑ Working with Students to Improve Indexing in Apache Hive
- ↑ Lam, Chuck (2010). Hadoop in Action. Manning Publications. ISBN 1-935182-19-6.
- ↑ Optimising Hadoop and Big Data with Text and HiveOptimising Hadoop and Big Data with Text and Hive
- ↑ LanguageManual ORC
- ↑ Faster Big Data on Hadoop with Hive and RCFile
- 1 2 3 Facebook's Petabyte Scale Data Warehouse using Hive and Hadoop
- ↑ Yongqiang He; Rubao Lee; Yin Huai; Zheng Shao; Namit Jain; Xiaodong Zhang; Zhiwei Xu. "RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems" (PDF).
- ↑ "Parquet". 18 Dec 2014. Archived from the original on 2 February 2015. Retrieved 2 February 2015.
- ↑ Massie, Matt (21 August 2013). "A Powerful Big Data Trio: Spark, Parquet and Avro". zenfractal.com. Archived from the original on 2 February 2015. Retrieved 2 February 2015.
- ↑ Franke, Jörn. "Hive & Bitcoin: Analytics on Blockchain data with SQL".
- ↑ Thusoo, Ashish; Sarma, Joydeep Sen; Jain, Namit; Shao, Zheng; Chakka, Prasad; Anthony, Suresh; Liu, Hao; Wyckoff, Pete; Murthy, Raghotham (2009-08-01). "Hive: A Warehousing Solution over a Map-reduce Framework". Proc. VLDB Endow. 2 (2): 1626–1629. doi:10.14778/1687553.1687609. ISSN 2150-8097.
- 1 2 "Design - Apache Hive - Apache Software Foundation". cwiki.apache.org. Retrieved 2016-09-12.
- ↑ "Abstract Syntax Tree". c2.com. Retrieved 2016-09-12.
- 1 2 Dokeroglu, Tansel; Ozal, Serkan; Bayir, MuratAli; Cinar, MuhammetSerkan; Cosar, Ahmet (2014-07-29). "Improving the performance of Hadoop Hive by sharing scan and computation tasks". Journal of Cloud Computing. 3 (1): 1–11. doi:10.1186/s13677-014-0012-6.
- ↑ "HiveServer - Apache Hive - Apache Software Foundation". cwiki.apache.org. Retrieved 2016-09-12.
- 1 2 3 White, Tom (2010). Hadoop: The Definitive Guide. O'Reilly Media. ISBN 978-1-4493-8973-4.
- ↑ Hive Language Manual
- ↑ ACID and Transactions in Hive
- ↑ Hive A Warehousing Solution Over a MapReduce Framework
- ↑ "Introduction to Hive transactions". datametica.com. Retrieved 2016-09-12.
- ↑ "Hive Transactions - Apache Hive - Apache Software Foundation". cwiki.apache.org. Retrieved 2016-09-12.
- ↑ "Configuration Properties - Apache Hive - Apache Software Foundation". cwiki.apache.org. Retrieved 2016-09-12.
External links
- Official website
- The Free Hive Book (CC by-nc licensed)
- Hive A Warehousing Solution Over a MapReduce Framework - Original paper presented by Facebook at VLDB 2009
- Using Apache Hive With Amazon Elastic MapReduce (Part 1) and Part 2 on YouTube, presented by an AWS Engineer
- Using hive + cassandra + shark. A hive cassandra cql storage handler.
- Major Technical Advancements in Apache Hive, Yin Huai, Ashutosh Chauhan, Alan Gates, Gunther Hagleitner, Eric N. Hanson, Owen O’Malley, Jitendra Pandey, Yuan Yuan, Rubao Lee and Xiaodong Zhang, SIGMOD 2014
- Apache Hive Wiki