Golomb coding
Golomb coding is a lossless data compression method using a family of data compression codes invented by Solomon W. Golomb in the 1960s. Alphabets following a geometric distribution will have a Golomb code as an optimal prefix code, making Golomb coding highly suitable for situations in which the occurrence of small values in the input stream is significantly more likely than large values.
Rice coding (invented by Robert F. Rice) denotes using a subset of the family of Golomb codes to produce a simpler (but possibly suboptimal) prefix code. Rice used this set of codes in an adaptive coding scheme; "Rice coding" can refer either to that adaptive scheme or to using that subset of Golomb codes. Whereas a Golomb code has a tunable parameter that can be any positive integer value, Rice codes are those in which the tunable parameter is a power of two. This makes Rice codes convenient for use on a computer since multiplication and division by 2 can be implemented more efficiently in binary arithmetic.
Rice coding is used as the entropy encoding stage in a number of lossless image compression and audio data compression methods.
Overview
Construction of codes
Golomb coding uses a tunable parameter to divide an input value into two parts: , the result of a division by , and , the remainder. The quotient is sent in unary coding, followed by the remainder in truncated binary encoding. When Golomb coding is equivalent to unary coding.





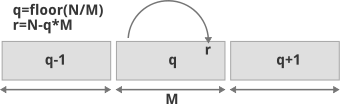
Golomb–Rice codes can be thought of as codes that indicate a number by the position of the bin (q), and the offset within the bin (r). The above figure shows the position q and offset r for the encoding of integer N using Golomb–Rice parameter M.
Formally, the two parts are given by the following expression, where is the number being encoded:


and
- .

The final result looks like: .

Note that can be of a varying number of bits. Specifically, is only b bits for Rice code and switches between b-1 and b bits for Golomb code (i.e. M is not a power of 2). Let . If , then use b-1 bits to encode r. If , then use b bits to encode r. Clearly, if M is a power of 2 and we can encode all values of r with b bits.




The parameter M is a function of the corresponding Bernoulli process, which is parameterized by the probability of success in a given Bernoulli trial. is either the median of the distribution or the median +/− 1. It can be determined by these inequalities:


Golomb states that for large M there is very little penalty for picking .

The Golomb code for this distribution is equivalent to the Huffman code for the same probabilities, if it were possible to compute the Huffman code.
Use with signed integers
Golomb's scheme was designed to encode sequences of non-negative numbers. However it is easily extended to accept sequences containing negative numbers using an overlap and interleave scheme, in which all values are reassigned to some positive number in a unique and reversible way. The sequence begins: 0, -1, 1, -2, 2, -3, 3, -4, 4 ... The nth negative value (i.e., -n) is mapped to the nth odd number (2n-1), and the mth positive value is mapped to the mth even number (2m). This may be expressed mathematically as follows: a positive value is mapped to (), and a negative value is mapped to (). This is an optimal prefix code only if both the positive and the magnitude of the negative values follow a geometric distribution with the same parameter.



Simple algorithm
Note below that this is the Rice–Golomb encoding, where the remainder code uses simple truncated binary encoding, also named "Rice coding" (other varying-length binary encodings, like arithmetic or Huffman encodings, are possible for the remainder codes, if the statistic distribution of remainder codes is not flat, and notably when not all possible remainders after the division are used). In this algorithm, if the M parameter is a power of 2, it becomes equivalent to the simpler Rice encoding.
- Fix the parameter M to an integer value.
- For N, the number to be encoded, find
- quotient = q = int[N/M]
- remainder = r = N modulo M
- Generate Codeword
- The Code format : <Quotient Code><Remainder Code>, where
- Quotient Code (in unary coding)
- Write a q-length string of 1 bits
- Write a 0 bit
- Remainder Code (in truncated binary encoding)
- If M is power of 2, code remainder as binary format. So bits are needed. (Rice code)
- If M is not a power of 2, set
- If code r as plain binary using b-1 bits.
- If code the number in plain binary representation using b bits.




Example
Set M = 10. Thus . The cutoff is


|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


For example, with a Rice–Golomb encoding of parameter M = 10, the decimal number 42 would first be split into q = 4,r = 2, and would be encoded as qcode(q),rcode(r) = qcode(4),rcode(2) = 11110,010 (you don't need to encode the separating comma in the output stream, because the 0 at the end of the q code is enough to say when q ends and r begins ; both the qcode and rcode are self-delimited).
Use for run-length encoding
Given an alphabet of two symbols, or a set of two events, P and Q, with probabilities p and (1 − p) respectively, where p ≥ 1/2, Golomb coding can be used to encode runs of zero or more P's separated by single Q's. In this application, the best setting of the parameter M is the nearest integer to . When p = 1/2, M = 1, and the Golomb code corresponds to unary (n ≥ 0 P's followed by a Q is encoded as n ones followed by a zero).

Applications
Numerous signal codecs use a Rice code for prediction residues. In predictive algorithms, such residues tend to fall into a two-sided geometric distribution, with small residues being more frequent than large residues, and the Rice code closely approximates the Huffman code for such a distribution without the overhead of having to transmit the Huffman table. One signal that does not match a geometric distribution is a sine wave, because the differential residues create a sinusoidal signal whose values are not creating a geometric distribution (the highest and lowest residue values have similar high frequency of occurrences, only the median positive and negative residues occur less often).
Several lossless audio codecs, such as Shorten,[1] FLAC,[2] Apple Lossless, and MPEG-4 ALS, use a Rice code after the linear prediction step (called "adaptive FIR filter" in Apple Lossless). Rice coding is also used in the FELICS lossless image codec.
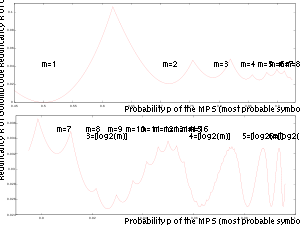
The Golomb–Rice coder is used in the entropy coding stage of Rice Algorithm based lossless image codecs. One such experiment yields a compression ratio graph given below. See other entries in this category at the bottom of this page. In those compression, the progressive space differential data yields an alternating suite of positive and negative values around 0, which are remapped to positive-only integers (by doubling the absolute value and adding one if the input is negative), and then Rice–Golomb coding is applied by varying the divisor which remains small.

In those results, the Rice coding may create very long sequences of one-bits for the quotient; for practical reasons, it is often necessary to limit the total run-length of one-bits, so a modified version of the Rice–Golomb encoding consists of replacing the long string of one-bits by encoding its length with a recursive Rice–Golomb encoding; this requires reserving some values in addition to the initial divisor k to allow the necessary distinction.
The JPEG-LS scheme uses Rice–Golomb to encode the prediction residuals.
References
- Golomb, S.W. (1966). , Run-length encodings. IEEE Transactions on Information Theory, IT--12(3):399--401
- R. F. Rice (1971) and R. Plaunt, , "Adaptive Variable-Length Coding for Efficient Compression of Spacecraft Television Data, " IEEE Transactions on Communications, vol. 16(9), pp. 889–897, Dec. 1971.
- R. F. Rice (1979), , "Some Practical Universal Noiseless Coding Techniques, " Jet Propulsion Laboratory, Pasadena, California, JPL Publication 79—22, Mar. 1979.
- Witten, Ian Moffat, Alistair Bell, Timothy. "Managing Gigabytes: Compressing and Indexing Documents and Images." Second Edition. Morgan Kaufmann Publishers, San Francisco CA. 1999 ISBN 1-55860-570-3
- David Salomon. "Data Compression",ISBN 0-387-95045-1.
- S. Büttcher, C. L. A. Clarke, and G. V. Cormack. Information Retrieval: Implementing and Evaluating Search Engines. MIT Press, Cambridge MA, 2010.
Data compression methods | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lossless |
| ||||||||||
| Audio |
| ||||||||||
| Image |
| ||||||||||
| Video |
| ||||||||||
| Theory | |||||||||||
| |||||||||||