PageRank
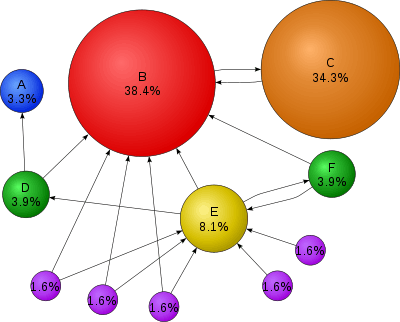
PageRank is an algorithm used by Google Search to rank websites in their search engine results. PageRank was named after Larry Page,[1] one of the founders of Google. PageRank is a way of measuring the importance of website pages. According to Google:
PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.[2]
It is not the only algorithm used by Google to order search engine results, but it is the first algorithm that was used by the company, and it is the best-known.[3][4]
Description

PageRank is a link analysis algorithm and it assigns a numerical weighting to each element of a hyperlinked set of documents, such as the World Wide Web, with the purpose of "measuring" its relative importance within the set. The algorithm may be applied to any collection of entities with reciprocal quotations and references. The numerical weight that it assigns to any given element E is referred to as the PageRank of E and denoted by Other factors like Author Rank can contribute to the importance of an entity.

A PageRank results from a mathematical algorithm based on the webgraph, created by all World Wide Web pages as nodes and hyperlinks as edges, taking into consideration authority hubs such as cnn.com or usa.gov. The rank value indicates an importance of a particular page. A hyperlink to a page counts as a vote of support. The PageRank of a page is defined recursively and depends on the number and PageRank metric of all pages that link to it ("incoming links"). A page that is linked to by many pages with high PageRank receives a high rank itself.
Numerous academic papers concerning PageRank have been published since Page and Brin's original paper.[5] In practice, the PageRank concept may be vulnerable to manipulation. Research has been conducted into identifying falsely influenced PageRank rankings. The goal is to find an effective means of ignoring links from documents with falsely influenced PageRank.[6]
Other link-based ranking algorithms for Web pages include the HITS algorithm invented by Jon Kleinberg (used by Teoma and now Ask.com),the IBM CLEVER project, the TrustRank algorithm and the hummingbird algorithm.
History
The eigenvalue problem was suggested in 1976 by Gabriel Pinski and Francis Narin, who worked on scientometrics ranking scientific journals [7] and in 1977 by Thomas Saaty in his concept of Analytic Hierarchy Process which weighted alternative choices.[8]
PageRank was developed at Stanford University by Larry Page and Sergey Brin in 1996 as part of a research project about a new kind of search engine.[9] Sergey Brin had the idea that information on the web could be ordered in a hierarchy by "link popularity": A page is ranked higher as there are more links to it.[10] It was co-authored by Rajeev Motwani and Terry Winograd. The first paper about the project, describing PageRank and the initial prototype of the Google search engine, was published in 1998:[5] shortly after, Page and Brin founded Google Inc., the company behind the Google search engine. While just one of many factors that determine the ranking of Google search results, PageRank continues to provide the basis for all of Google's web search tools.[11]
The name "PageRank" plays off of the name of developer Larry Page, as well as the concept of a web page.[12] The word is a trademark of Google, and the PageRank process has been patented (U.S. Patent 6,285,999). However, the patent is assigned to Stanford University and not to Google. Google has exclusive license rights on the patent from Stanford University. The university received 1.8 million shares of Google in exchange for use of the patent; the shares were sold in 2005 for $336 million.[13][14]
PageRank was influenced by citation analysis, early developed by Eugene Garfield in the 1950s at the University of Pennsylvania, and by Hyper Search, developed by Massimo Marchiori at the University of Padua. In the same year PageRank was introduced (1998), Jon Kleinberg published his important work on HITS. Google's founders cite Garfield, Marchiori, and Kleinberg in their original papers.[5][15]
A small search engine called "RankDex" from IDD Information Services designed by Robin Li was, since 1996, already exploring a similar strategy for site-scoring and page ranking.[16] The technology in RankDex would be patented by 1999[17] and used later when Li founded Baidu in China.[18][19] Li's work would be referenced by some of Larry Page's U.S. patents for his Google search methods.[20]
Algorithm
The PageRank algorithm outputs a probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page. PageRank can be calculated for collections of documents of any size. It is assumed in several research papers that the distribution is evenly divided among all documents in the collection at the beginning of the computational process. The PageRank computations require several passes, called "iterations", through the collection to adjust approximate PageRank values to more closely reflect the theoretical true value.
A probability is expressed as a numeric value between 0 and 1. A 0.5 probability is commonly expressed as a "50% chance" of something happening. Hence, a PageRank of 0.5 means there is a 50% chance that a person clicking on a random link will be directed to the document with the 0.5 PageRank.
Simplified algorithm
Assume a small universe of four web pages: A, B, C and D. Links from a page to itself, or multiple outbound links from one single page to another single page, are ignored. PageRank is initialized to the same value for all pages. In the original form of PageRank, the sum of PageRank over all pages was the total number of pages on the web at that time, so each page in this example would have an initial value of 1. However, later versions of PageRank, and the remainder of this section, assume a probability distribution between 0 and 1. Hence the initial value for each page in this example is 0.25.
The PageRank transferred from a given page to the targets of its outbound links upon the next iteration is divided equally among all outbound links.
If the only links in the system were from pages B, C, and D to A, each link would transfer 0.25 PageRank to A upon the next iteration, for a total of 0.75.

Suppose instead that page B had a link to pages C and A, page C had a link to page A, and page D had links to all three pages. Thus, upon the first iteration, page B would transfer half of its existing value, or 0.125, to page A and the other half, or 0.125, to page C. Page C would transfer all of its existing value, 0.25, to the only page it links to, A. Since D had three outbound links, it would transfer one third of its existing value, or approximately 0.083, to A. At the completion of this iteration, page A will have a PageRank of approximately 0.458.

In other words, the PageRank conferred by an outbound link is equal to the document's own PageRank score divided by the number of outbound links L( ).

In the general case, the PageRank value for any page u can be expressed as:
- ,

i.e. the PageRank value for a page u is dependent on the PageRank values for each page v contained in the set Bu (the set containing all pages linking to page u), divided by the number L(v) of links from page v.
Damping factor
The PageRank theory holds that an imaginary surfer who is randomly clicking on links will eventually stop clicking. The probability, at any step, that the person will continue is a damping factor d. Various studies have tested different damping factors, but it is generally assumed that the damping factor will be set around 0.85.[5]
The damping factor is subtracted from 1 (and in some variations of the algorithm, the result is divided by the number of documents (N) in the collection) and this term is then added to the product of the damping factor and the sum of the incoming PageRank scores. That is,

So any page's PageRank is derived in large part from the PageRanks of other pages. The damping factor adjusts the derived value downward. The original paper, however, gave the following formula, which has led to some confusion:

The difference between them is that the PageRank values in the first formula sum to one, while in the second formula each PageRank is multiplied by N and the sum becomes N. A statement in Page and Brin's paper that "the sum of all PageRanks is one"[5] and claims by other Google employees[21] support the first variant of the formula above.
Page and Brin confused the two formulas in their most popular paper "The Anatomy of a Large-Scale Hypertextual Web Search Engine", where they mistakenly claimed that the latter formula formed a probability distribution over web pages.[5]
Google recalculates PageRank scores each time it crawls the Web and rebuilds its index. As Google increases the number of documents in its collection, the initial approximation of PageRank decreases for all documents.
The formula uses a model of a random surfer who gets bored after several clicks and switches to a random page. The PageRank value of a page reflects the chance that the random surfer will land on that page by clicking on a link. It can be understood as a Markov chain in which the states are pages, and the transitions, which are all equally probable, are the links between pages.
If a page has no links to other pages, it becomes a sink and therefore terminates the random surfing process. If the random surfer arrives at a sink page, it picks another URL at random and continues surfing again.
When calculating PageRank, pages with no outbound links are assumed to link out to all other pages in the collection. Their PageRank scores are therefore divided evenly among all other pages. In other words, to be fair with pages that are not sinks, these random transitions are added to all nodes in the Web, with a residual probability usually set to d = 0.85, estimated from the frequency that an average surfer uses his or her browser's bookmark feature.
So, the equation is as follows:

where are the pages under consideration, is the set of pages that link to , is the number of outbound links on page , and N is the total number of pages.





The PageRank values are the entries of the dominant right eigenvector of the modified adjacency matrix. This makes PageRank a particularly elegant metric: the eigenvector is

where R is the solution of the equation

where the adjacency function is 0 if page does not link to , and normalized such that, for each j

- ,

i.e. the elements of each column sum up to 1, so the matrix is a stochastic matrix (for more details see the computation section below). Thus this is a variant of the eigenvector centrality measure used commonly in network analysis.
Because of the large eigengap of the modified adjacency matrix above,[22] the values of the PageRank eigenvector can be approximated to within a high degree of accuracy within only a few iterations.
Google's founders, in their original paper,[15] reported that the PageRank algorithm for a network consisting of 322 million links (in-edges and out-edges) converges to within a tolerable limit in 52 iterations. The convergence in a network of half the above size took approximately 45 iterations. Through this data, they concluded the algorithm can be scaled very well and that the scaling factor for extremely large networks would be roughly linear in , where n is the size of the network.

As a result of Markov theory, it can be shown that the PageRank of a page is the probability of arriving at that page after a large number of clicks. This happens to equal where is the expectation of the number of clicks (or random jumps) required to get from the page back to itself.


One main disadvantage of PageRank is that it favors older pages. A new page, even a very good one, will not have many links unless it is part of an existing site (a site being a densely connected set of pages, such as Wikipedia).
Several strategies have been proposed to accelerate the computation of PageRank.[23]
Various strategies to manipulate PageRank have been employed in concerted efforts to improve search results rankings and monetize advertising links. These strategies have severely impacted the reliability of the PageRank concept, which purports to determine which documents are actually highly valued by the Web community.
Since December 2007, when it started actively penalizing sites selling paid text links, Google has combatted link farms and other schemes designed to artificially inflate PageRank. How Google identifies link farms and other PageRank manipulation tools is among Google's trade secrets.
Computation
PageRank can be computed either iteratively or algebraically. The iterative method can be viewed as the power iteration method[24][25] or the power method. The basic mathematical operations performed are identical.
Iterative
At , an initial probability distribution is assumed, usually

- .

At each time step, the computation, as detailed above, yields
- ,

or in matrix notation
- , (*)

where and is the column vector of length containing only ones.



The matrix is defined as


i.e.,
- ,

where denotes the adjacency matrix of the graph and is the diagonal matrix with the outdegrees in the diagonal.


The computation ends when for some small

- ,

i.e., when convergence is assumed.
Algebraic
—For (i.e., in the steady state), the above equation (*) reads

- . (**)

The solution is given by
- ,

with the identity matrix .

The solution exists and is unique for . This can be seen by noting that is by construction a stochastic matrix and hence has an eigenvalue equal to one as a consequence of the Perron–Frobenius theorem.

Power Method
If the matrix is a transition probability, i.e., column-stochastic and is a probability distribution (i.e., , where is matrix of all ones), Eq. (**) is equivalent to




- . (***)

Hence PageRank is the principal eigenvector of . A fast and easy way to compute this is using the power method: starting with an arbitrary vector , the operator is applied in succession, i.e.,


- ,

until
- .

Note that in Eq. (***) the matrix on the right-hand side in the parenthesis can be interpreted as
- ,

where is an initial probability distribution. In the current case

- .

Finally, if has columns with only zero values, they should be replaced with the initial probability vector . In other words,
- ,

where the matrix is defined as

- ,

with

In this case, the above two computations using only give the same PageRank if their results are normalized:
- .

PageRank MATLAB/Octave implementation
% Parameter M adjacency matrix where M_i,j represents the link from 'j' to 'i', such that for all 'j'
% sum(i, M_i,j) = 1
% Parameter d damping factor
% Parameter v_quadratic_error quadratic error for v
% Return v, a vector of ranks such that v_i is the i-th rank from [0, 1]
function [v] = rank2(M, d, v_quadratic_error)
N = size(M, 2); % N is equal to either dimension of M and the number of documents
v = rand(N, 1);
v = v ./ norm(v, 1); % This is now L1, not L2
last_v = ones(N, 1) * inf;
M_hat = (d .* M) + (((1 - d) / N) .* ones(N, N));
while(norm(v - last_v, 2) > v_quadratic_error)
last_v = v;
v = M_hat * v;
% removed the L2 norm of the iterated PR
end
endfunction
Example of code calling the rank function defined above:
M = [0 0 0 0 1 ; 0.5 0 0 0 0 ; 0.5 0 0 0 0 ; 0 1 0.5 0 0 ; 0 0 0.5 1 0];
rank(M, 0.80, 0.001)
This example takes 13 iterations to converge.
Variations
PageRank of an undirected graph
The PageRank of an undirected graph G is statistically close to the degree distribution of the graph G,[26] but they are generally not identical: If R is the PageRank vector defined above, and D is the degree distribution vector

where denotes the degree of vertex , and E is the edge-set of the graph, then, with , by:[27]



that is, the PageRank of an undirected graph equals to the degree distribution vector if and only if the graph is regular, i.e., every vertex has the same degree.
Distributed algorithm for PageRank computation
There are simple and fast random walk-based distributed algorithms for computing PageRank of nodes in a network.[28] They present a simple algorithm that takes rounds with high probability on any graph (directed or undirected), where n is the network size and is the reset probability ( is also called as damping factor) used in the PageRank computation. They also present a faster algorithm that takes rounds in undirected graphs. Both of the above algorithms are scalable, as each node processes and sends only small (polylogarithmic in n, the network size) number of bits per round.



Google Toolbar
The Google Toolbar long had a PageRank feature which displayed a visited page's PageRank as a whole number between 0 and 10. The most popular websites displayed a PageRank of 10. The least showed a PageRank of 0. Google has not disclosed the specific method for determining a Toolbar PageRank value, which is to be considered only a rough indication of the value of a website. In March 2016 Google announced it would no longer support this feature, and the underlying API would soon cease to operate.[29]
SERP rank
The search engine results page (SERP) is the actual result returned by a search engine in response to a keyword query. The SERP consists of a list of links to web pages with associated text snippets. The SERP rank of a web page refers to the placement of the corresponding link on the SERP, where higher placement means higher SERP rank. The SERP rank of a web page is a function not only of its PageRank, but of a relatively large and continuously adjusted set of factors (over 200),.[30] Search engine optimization (SEO) is aimed at influencing the SERP rank for a website or a set of web pages.
Positioning of a webpage on Google SERPs for a keyword depends on relevance and reputation, also known as authority and popularity. PageRank is Google’s indication of its assessment of the reputation of a webpage: It is non-keyword specific. Google uses a combination of webpage and website authority to determine the overall authority of a webpage competing for a keyword.[31] The PageRank of the HomePage of a website is the best indication Google offers for website authority.[32]
After the introduction of Google Places into the mainstream organic SERP, numerous other factors in addition to PageRank affect ranking a business in Local Business Results.[33]
Google directory PageRank
The Google Directory PageRank was an 8-unit measurement. Unlike the Google Toolbar, which shows a numeric PageRank value upon mouseover of the green bar, the Google Directory only displayed the bar, never the numeric values. Google Directory was closed on July 20, 2011.[34]
False or spoofed PageRank
In the past, the PageRank shown in the Toolbar was easily manipulated. Redirection from one page to another, either via a HTTP 302 response or a "Refresh" meta tag, caused the source page to acquire the PageRank of the destination page. Hence, a new page with PR 0 and no incoming links could have acquired PR 10 by redirecting to the Google home page. This spoofing technique was a known vulnerability. Spoofing can generally be detected by performing a Google search for a source URL; if the URL of an entirely different site is displayed in the results, the latter URL may represent the destination of a redirection.
Manipulating PageRank
For search engine optimization purposes, some companies offer to sell high PageRank links to webmasters.[35] As links from higher-PR pages are believed to be more valuable, they tend to be more expensive. It can be an effective and viable marketing strategy to buy link advertisements on content pages of quality and relevant sites to drive traffic and increase a webmaster's link popularity. However, Google has publicly warned webmasters that if they are or were discovered to be selling links for the purpose of conferring PageRank and reputation, their links will be devalued (ignored in the calculation of other pages' PageRanks). The practice of buying and selling links is intensely debated across the Webmaster community. Google advises webmasters to use the nofollow HTML attribute value on sponsored links. According to Matt Cutts, Google is concerned about webmasters who try to game the system, and thereby reduce the quality and relevance of Google search results.[35]
The intentional surfer model
The original PageRank algorithm reflects the so-called random surfer model, meaning that the PageRank of a particular page is derived from the theoretical probability of visiting that page when clicking on links at random. A page ranking model that reflects the importance of a particular page as a function of how many actual visits it receives by real users is called the intentional surfer model.[36]
Directed Surfer Model
A more intelligent surfer that probabilistically hops from page to page depending on the content of the pages and query terms the surfer that it is looking for. This model is based on a query-dependent PageRank score of a page which as the name suggests is also a function of query. When given a multiple-term query, Q={q1,q2,…}, the surfer selects a q according to some probability distribution, P(q) and uses that term to guide its behavior for a large number of steps. It then selects another term according to the distribution to determine its behavior, and so on. The resulting distribution over visited web pages is QD-PageRank.[37]
Social components
The PageRank algorithm has major effects on society as it contains a social influence. As opposed to the scientific viewpoint of PageRank as an algorithm the humanities instead view it through a lens examining its social components. In these instances, it is dissected and reviewed not for its technological advancement in the field of search engines, but for its societal influences.
[38] Laura Granka discusses PageRank by describing how the pages are not simply ranked via popularity as they contain a reliability that gives them a trustworthy quality. This has led to a development of behavior that is directly linked to PageRank. PageRank is viewed as the definitive rank of products and businesses and thus, can manipulate thinking. The information that is available to individuals is what shapes thinking and ideology and PageRank is the device that displays this information. The results shown are the forum to which information is delivered to the public and these results have a societal impact as they will affect how a person thinks and acts.
[39] Katja Mayer views PageRank as a social network as it connects differing viewpoints and thoughts in a single place. People go to PageRank for information and are flooded with citations of other authors who also have an opinion on the topic. This creates a social aspect where everything can be discussed and collected to provoke thinking. There is a social relationship that exists between PageRank and the people who use it as it is constantly adapting and changing to the shifts in modern society. Viewing the relationship between PageRank and the individual through sociometry allows for an in-depth look at the connection that results.
[40] Matteo Pasquinelli reckons the basis for the belief that PageRank has a social component lies in the idea of attention economy. With attention economy, value is placed on products that receive a greater amount of human attention and the results at the top of the PageRank garner a larger amount of focus then those on subsequent pages. The outcomes with the higher PageRank will therefore enter the human consciousness to a larger extent. These ideas can influence decision-making and the actions of the viewer have a direct relation to the PageRank. They possess a higher potential to attract a user’s attention as their location increases the attention economy attached to the site. With this location they can receive more traffic and their online marketplace will have more purchases. The PageRank of these sites allow them to be trusted and they are able to parlay this trust into increased business.
Other uses
The mathematics of PageRank are entirely general and apply to any graph or network in any domain. Thus, PageRank is now regularly used in bibliometrics, social and information network analysis, and for link prediction and recommendation. It's even used for systems analysis of road networks, as well as biology, chemistry, neuroscience, and physics.[41]
Personalized PageRank is used by Twitter to present users with other accounts they may wish to follow.[42]
Swiftype's site search product builds a "PageRank that’s specific to individual websites" by looking at each website's signals of importance and prioritizing content based on factors such as number of links from the home page.[43]
A version of PageRank has recently been proposed as a replacement for the traditional Institute for Scientific Information (ISI) impact factor,[44] and implemented at Eigenfactor as well as at SCImago. Instead of merely counting total citation to a journal, the "importance" of each citation is determined in a PageRank fashion.
A similar new use of PageRank is to rank academic doctoral programs based on their records of placing their graduates in faculty positions. In PageRank terms, academic departments link to each other by hiring their faculty from each other (and from themselves).[45]
PageRank has been used to rank spaces or streets to predict how many people (pedestrians or vehicles) come to the individual spaces or streets.[46][47] In lexical semantics it has been used to perform Word Sense Disambiguation,[48] Semantic similarity,[49] and also to automatically rank WordNet synsets according to how strongly they possess a given semantic property, such as positivity or negativity.[50]
A Web crawler may use PageRank as one of a number of importance metrics it uses to determine which URL to visit during a crawl of the web. One of the early working papers [51] that were used in the creation of Google is Efficient crawling through URL ordering,[52] which discusses the use of a number of different importance metrics to determine how deeply, and how much of a site Google will crawl. PageRank is presented as one of a number of these importance metrics, though there are others listed such as the number of inbound and outbound links for a URL, and the distance from the root directory on a site to the URL.
The PageRank may also be used as a methodology to measure the apparent impact of a community like the Blogosphere on the overall Web itself. This approach uses therefore the PageRank to measure the distribution of attention in reflection of the Scale-free network paradigm.
In any ecosystem, a modified version of PageRank may be used to determine species that are essential to the continuing health of the environment.[53]
For the analysis of protein networks in biology PageRank is also a useful tool.[54] [55]
In 2005, in a pilot study in Pakistan, Structural Deep Democracy, SD2[56][57] was used for leadership selection in a sustainable agriculture group called Contact Youth. SD2 uses PageRank for the processing of the transitive proxy votes, with the additional constraints of mandating at least two initial proxies per voter, and all voters are proxy candidates. More complex variants can be built on top of SD2, such as adding specialist proxies and direct votes for specific issues, but SD2 as the underlying umbrella system, mandates that generalist proxies should always be used.
Pagerank has recently been used to quantify the scientific impact of researchers. The underlying citation and collaboration networks are used in conjunction with pagerank algorithm in order to come up with a ranking system for individual publications which propagates to individual authors. The new index known as pagerank-index (Pi) is demonstrated to be fairer compared to h-index in the context of many drawbacks exhibited by h-index.[58]
nofollow
In early 2005, Google implemented a new value, "nofollow",[59] for the rel attribute of HTML link and anchor elements, so that website developers and bloggers can make links that Google will not consider for the purposes of PageRank—they are links that no longer constitute a "vote" in the PageRank system. The nofollow relationship was added in an attempt to help combat spamdexing.
As an example, people could previously create many message-board posts with links to their website to artificially inflate their PageRank. With the nofollow value, message-board administrators can modify their code to automatically insert "rel='nofollow'" to all hyperlinks in posts, thus preventing PageRank from being affected by those particular posts. This method of avoidance, however, also has various drawbacks, such as reducing the link value of legitimate comments. (See: Spam in blogs#nofollow)
In an effort to manually control the flow of PageRank among pages within a website, many webmasters practice what is known as PageRank Sculpting[60]—which is the act of strategically placing the nofollow attribute on certain internal links of a website in order to funnel PageRank towards those pages the webmaster deemed most important. This tactic has been used since the inception of the nofollow attribute, but may no longer be effective since Google announced that blocking PageRank transfer with nofollow does not redirect that PageRank to other links.[61]
Deprecation
PageRank was once available for the verified site maintainers through the Google Webmaster Tools interface. However, on October 15, 2009, a Google employee confirmed that the company had removed PageRank from its Webmaster Tools section, saying that "We've been telling people for a long time that they shouldn't focus on PageRank so much. Many site owners seem to think it's the most important metric for them to track, which is simply not true."[62] In addition, The PageRank indicator is not available in Google's own Chrome browser.
The visible page rank is updated very infrequently. It was last updated in November 2013. In October 2014 Matt Cutts announced that another visible pagerank update would not be coming.[63]
Even though "Toolbar" PageRank is less important for SEO purposes, the existence of back-links from more popular websites continues to push a webpage higher up in search rankings.[64]
Google elaborated on the reasons for PageRank deprecation at Q&A #March and announced Links and Content as the Top Ranking Factors, RankBrain was announced as the #3 Ranking Factor in October 2015 so the Top 3 Factors are now confirmed officially by Google.[65]
On April 15, 2016 Google has officially shut down their Google Toolbar PageRank Data to public. Google had told about this earlier that they would be removing the PageRank score from the google toolbar months before in advance.[66]
See also
- EigenTrust — a decentralized PageRank algorithm
- Google bomb
- Google Search
- Google matrix
- Google Panda
- VisualRank - Google's application of PageRank to image-search
- Hilltop algorithm
- Katz centrality – a 1953 scheme closely related to pagerank
- Link love
- Methods of website linking
- Power method — the iterative eigenvector algorithm used to calculate PageRank
- Search engine optimization
- SimRank — a measure of object-to-object similarity based on random-surfer model
- Topic-Sensitive PageRank
- TrustRank
- Webgraph
- CheiRank
- Google Penguin
- Google Hummingbird
Notes
- ↑ "Google Press Center: Fun Facts". www.google.com. Archived from the original on 2001-07-15.
- ↑ "Facts about Google and Competition". Archived from the original on 4 November 2011. Retrieved 12 July 2014.
- ↑ Sullivan, Danny. "What Is Google PageRank? A Guide For Searchers & Webmasters". Search Engine Land.
- ↑ Cutts, Matt. "Algorithms Rank Relevant Results Higher". www.google.com. Archived from the original on July 2, 2013. Retrieved 19 October 2015.
- 1 2 3 4 5 6 Brin, S.; Page, L. (1998). "The anatomy of a large-scale hypertextual Web search engine" (PDF). Computer Networks and ISDN Systems. 30: 107–117. doi:10.1016/S0169-7552(98)00110-X. ISSN 0169-7552.
- ↑ Gyöngyi, Zoltán; Berkhin, Pavel; Garcia-Molina, Hector; Pedersen, Jan (2006), "Link spam detection based on mass estimation", Proceedings of the 32nd International Conference on Very Large Data Bases (VLDB '06, Seoul, Korea) (PDF), pp. 439–450.
- ↑ Gabriel Pinski & Francis Narin. "Citation influence for journal aggregates of scientific publications: Theory, with application to the literature of physics". Information Processing & Management. 12 (5): 297–312. doi:10.1016/0306-4573(76)90048-0.
- ↑ Thomas Saaty (1977). "A scaling method for priorities in hierarchical structures". Journal of Mathematical Psychology. 15 (3): 234–281. doi:10.1016/0022-2496(77)90033-5.
- ↑ Page, Larry, "PageRank: Bringing Order to the Web" at the Wayback Machine (archived May 6, 2002), Stanford Digital Library Project, talk. August 18, 1997 (archived 2002)
- ↑ 187-page study from Graz University, Austria, includes the note that also human brains are used when determining the page rank in Google
- ↑ "Our products and services". Google.com. Retrieved 2011-05-27.
- ↑ David Vise & Mark Malseed (2005). The Google Story. p. 37. ISBN 0-553-80457-X.
- ↑ Lisa M. Krieger (1 December 2005). "Stanford Earns $336 Million Off Google Stock". San Jose Mercury News, cited by redOrbit. Retrieved 2009-02-25.
- ↑ Richard Brandt. "Starting Up. How Google got its groove". Stanford magazine. Retrieved 2009-02-25.
- 1 2 Page, Lawrence; Brin, Sergey; Motwani, Rajeev and Winograd, Terry (1999). "The PageRank citation ranking: Bringing order to the Web". Cite uses deprecated parameter
|coauthors=(help), published as a technical report on January 29, 1998 PDF - ↑ Li, Yanhong (August 6, 2002). "Toward a qualitative search engine". Internet Computing, IEEE. IEEE Computer Society. 2 (4): 24–29. doi:10.1109/4236.707687.
- ↑ USPTO, "Hypertext Document Retrieval System and Method", U.S. Patent number: 5920859, Inventor: Yanhong Li, Filing date: Feb 5, 1997, Issue date: Jul 6, 1999
- ↑ Greenberg, Andy, "The Man Who's Beating Google", Forbes magazine, October 05, 2009
- ↑ "About: RankDex", rankdex.com
- ↑ "Method for node ranking in a linked database". www.google.com. Google Patents. Retrieved 19 October 2015.
- ↑ Matt Cutts's blog: Straight from Google: What You Need to Know, see page 15 of his slides.
- ↑ Taher Haveliwala & Sepandar Kamvar. (March 2003). "The Second Eigenvalue of the Google Matrix" (PDF). Stanford University Technical Report: 7056. arXiv:math/0307056
 . Bibcode:2003math......7056N.
. Bibcode:2003math......7056N. - ↑ Gianna M. Del Corso; Antonio Gullí; Francesco Romani (2005). "Fast PageRank Computation via a Sparse Linear System". Internet Mathematics. Lecture Notes in Computer Science. 2 (3): 118–130. doi:10.1007/978-3-540-30216-2_10. ISBN 978-3-540-23427-2.
- ↑ Arasu, A. and Novak, J. and Tomkins, A. and Tomlin, J. (2002). "PageRank computation and the structure of the web: Experiments and algorithms". Proceedings of the Eleventh International World Wide Web Conference, Poster Track. Brisbane, Australia. pp. 107–117.
- ↑ Massimo Franceschet (2010). "PageRank: Standing on the shoulders of giants". arXiv:1002.2858 [cs.IR].
- ↑ Nicola Perra and Santo Fortunato.; Fortunato (September 2008). "Spectral centrality measures in complex networks". Phys. Rev. E. 78 (3): 36107. arXiv:0805.3322. Bibcode:2008PhRvE..78c6107P. doi:10.1103/PhysRevE.78.036107.
- ↑ Vince Grolmusz (2015). "A Note on the PageRank of Undirected Graphs". Information Processing Letters. 115: 633–634. doi:10.1016/j.ipl.2015.02.015.
- ↑ Atish Das Sarma; Anisur Rahaman Molla; Gopal Pandurangan; Eli Upfal (2012). "Fast Distributed PageRank Computation". arXiv:1208.3071 [cs.DC,cs.DS].
- ↑ Schwartz, Barry (March 8, 2016). "Google has confirmed it is removing Toolbar PageRank". Search Engine Land.
- ↑ Fishkin, Rand; Jeff Pollard (April 2, 2007). "Search Engine Ranking Factors - Version 2". seomoz.org. Retrieved May 11, 2009.
- ↑ Dover, D. Search Engine Optimization Secrets Indianapolis. Wiley. 2011.
- ↑ Viniker, D. The Importance of Keyword Difficulty Screening for SEO. Ed. Schwartz, M. Digital Guidebook Volume 5. News Press. p 160–164.
- ↑ "Ranking of listings : Ranking - Google Places Help". Google.com. Retrieved 2011-05-27.
- ↑ Google Directory#Google Directory
- 1 2 "How to report paid links". mattcutts.com/blog. April 14, 2007. Retrieved 2007-05-28.
- ↑ Jøsang, A. (2007). "Trust and Reputation Systems". In Aldini, A. Foundations of Security Analysis and Design IV, FOSAD 2006/2007 Tutorial Lectures. (PDF). 4677. Springer LNCS 4677. pp. 209–245. doi:10.1007/978-3-540-74810-6.
- ↑ Matthew Richardson & Pedro Domingos, A. (2001). The Intelligent Surfer:Probabilistic Combination of Link and Content Information in PageRank (PDF).
- ↑ Granka, Laura A. (2010-09-27). "The Politics of Search: A Decade Retrospective". The Information Society. 26 (5): 364–374. doi:10.1080/01972243.2010.511560. ISSN 0197-2243.
- ↑ Mayer, Katja (2009). Deep Search: The Politics of Search beyond Google, On the Sociometry of Search Engines. Studien Verlag.
- ↑ Pasquinelli, Matteo (2009). Deep Search: The Politics of Search beyond Google, Diagram of the Cognitive Capitalism and the Rentier of the Common Intellect. Studien Verlag.
- ↑ Gleich, David F. (January 2015). "PageRank Beyond the Web". SIAM Review. 57 (3): 321–363. arXiv:1407.5107. doi:10.1137/140976649.
- ↑ Pankaj Gupta, Ashish Goel, Jimmy Lin, Aneesh Sharma, Dong Wang, and Reza Bosagh Zadeh WTF: The who-to-follow system at Twitter, Proceedings of the 22nd international conference on World Wide Web
- ↑ Ha, Anthony (2012-05-08). "Y Combinator-Backed Swiftype Builds Site Search That Doesn't Suck". TechCrunch. Retrieved 2014-07-08.
- ↑ Johan Bollen, Marko A. Rodriguez, and Herbert Van de Sompel.; Rodriguez; Van De Sompel (December 2006). "Journal Status". Scientometrics. 69 (3): 1030. arXiv:cs.GL/0601030. Bibcode:2006cs........1030B. doi:10.1145/1255175.1255273.
- ↑ Benjamin M. Schmidt & Matthew M. Chingos (2007). "Ranking Doctoral Programs by Placement: A New Method" (PDF). PS: Political Science and Politics. 40 (July): 523–529. doi:10.1017/s1049096507070771.
- ↑ B. Jiang (2006). "Ranking spaces for predicting human movement in an urban environment". International Journal of Geographical Information Science. 23 (7): 823–837. arXiv:physics/0612011. doi:10.1080/13658810802022822.
- ↑ Jiang B.; Zhao S. & Yin J. (2008). "Self-organized natural roads for predicting traffic flow: a sensitivity study". Journal of Statistical Mechanics: Theory and Experiment. P07008 (7): 008. arXiv:0804.1630. Bibcode:2008JSMTE..07..008J. doi:10.1088/1742-5468/2008/07/P07008.
- ↑ Roberto Navigli, Mirella Lapata. "An Experimental Study of Graph Connectivity for Unsupervised Word Sense Disambiguation". IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 32(4), IEEE Press, 2010, pp. 678–692.
- ↑ M. T. Pilehvar, D. Jurgens and R. Navigli. Align, Disambiguate and Walk: A Unified Approach for Measuring Semantic Similarity.. Proc. of the 51st Annual Meeting of the Association for Computational Linguistics (ACL 2013), Sofia, Bulgaria, August 4–9, 2013, pp. 1341-1351.
- ↑ Andrea Esuli & Fabrizio Sebastiani. "PageRanking WordNet synsets: An Application to Opinion-Related Properties" (PDF). In Proceedings of the 35th Meeting of the Association for Computational Linguistics, Prague, CZ, 2007, pp. 424–431. Retrieved June 30, 2007.
- ↑ "Working Papers Concerning the Creation of Google". Google. Retrieved November 29, 2006.
- ↑ Cho, J., Garcia-Molina, H., and Page, L. (1998). "Efficient crawling through URL ordering". Proceedings of the seventh conference on World Wide Web. Brisbane, Australia.
- ↑ Burns, Judith (2009-09-04). "Google trick tracks extinctions". BBC News. Retrieved 2011-05-27.
- ↑ G. Ivan & V. Grolmusz (2011). "When the Web meets the cell: using personalized PageRank for analyzing protein interaction networks". Bioinformatics. Vol. 27, No. 3. pp. 405-407. 27 (3): 405–7. doi:10.1093/bioinformatics/btq680. PMID 21149343.
- ↑ D. Banky and G. Ivan and V. Grolmusz (2013). "Equal opportunity for low-degree network nodes: a PageRank-based method for protein target identification in metabolic graphs". PLOS ONE. Vol. 8, No. 1. e54204. 8 (1): 405–7. Bibcode:2013PLoSO...854204B. doi:10.1371/journal.pone.0054204. PMC 3558500. PMID 23382878.
- ↑ "Yahoo! Groups". Groups.yahoo.com. Retrieved 2013-10-02.
- ↑ "CiteSeerX — Autopoietic Information Systems in Modern Organizations". Citeseerx.ist.psu.edu. Retrieved 2013-10-02.
- ↑ Senanayake, Upul; Piraveenan, Mahendra; Zomaya, Albert (2015). "The Pagerank-Index: Going beyond Citation Counts in Quantifying Scientific Impact of Researchers". PLOS ONE. 10 (8): e0134794. doi:10.1371/journal.pone.0134794. ISSN 1932-6203.
- ↑ "Preventing Comment Spam". Google. Retrieved January 1, 2005.
- ↑ "PageRank Sculpting: Parsing the Value and Potential Benefits of Sculpting PR with Nofollow". SEOmoz. Retrieved 2011-05-27.
- ↑ "PageRank sculpting". Mattcutts.com. 2009-06-15. Retrieved 2011-05-27.
- ↑ Susan Moskwa. "PageRank Distribution Removed From WMT". Retrieved October 16, 2009
- ↑ Bartleman, Wil (2014-10-12). "Google Page Rank Update is Not Coming". Managed Admin. Retrieved 2014-10-12.
- ↑ "So...You Think SEO Has Changed". 19 March 2014.
- ↑ Clark, Jack. "Google Turning Its Lucrative Web Search Over to AI Machines". Bloomberg. Retrieved 26 March 2016.
- ↑ Schwartz, Barry. "Google Toolbar PageRank officially goes dark". Search Engine Land.
References
- Altman, Alon; Moshe Tennenholtz (2005). "Ranking Systems: The PageRank Axioms" (PDF). Proceedings of the 6th ACM conference on Electronic commerce (EC-05). Vancouver, BC. Retrieved 29 September 2014.
- Cheng, Alice; Eric J. Friedman (2006-06-11). "Manipulability of PageRank under Sybil Strategies" (PDF). Proceedings of the First Workshop on the Economics of Networked Systems (NetEcon06). Ann Arbor, Michigan. Retrieved 2008-01-22.
- Farahat, Ayman; LoFaro, Thomas; Miller, Joel C.; Rae, Gregory and Ward, Lesley A. (2006). "Authority Rankings from HITS, PageRank, and SALSA: Existence, Uniqueness, and Effect of Initialization". SIAM Journal on Scientific Computing. 27 (4): 1181–1201. doi:10.1137/S1064827502412875.
- Haveliwala, Taher; Jeh, Glen; Kamvar, Sepandar (2003). "An Analytical Comparison of Approaches to Personalizing PageRank" (PDF). Stanford University Technical Report.
- Langville, Amy N.; Meyer, Carl D. (2003). "Survey: Deeper Inside PageRank". Internet Mathematics. 1 (3).
- Langville, Amy N.; Meyer, Carl D. (2006). Google's PageRank and Beyond: The Science of Search Engine Rankings. Princeton University Press. ISBN 0-691-12202-4.
- Richardson, Matthew; Domingos, Pedro (2002). "The intelligent surfer: Probabilistic combination of link and content information in PageRank" (PDF). Proceedings of Advances in Neural Information Processing Systems. 14.
Relevant patents
- Original PageRank U.S. Patent—Method for node ranking in a linked database—Patent number 6,285,999—September 4, 2001
- PageRank U.S. Patent—Method for scoring documents in a linked database—Patent number 6,799,176—September 28, 2004
- PageRank U.S. Patent—Method for node ranking in a linked database—Patent number 7,058,628—June 6, 2006
- PageRank U.S. Patent—Scoring documents in a linked database—Patent number 7,269,587—September 11, 2007
External links
- Algorithms by Google
- Our products and services by Google
- How Google Finds Your Needle in the Web's Haystack by the American Mathematical Society