Head/tail Breaks

Head/tail breaks is a new clustering algorithm scheme for data with a heavy-tailed distribution such as power laws and lognormal distributions. The heavy-tailed distribution can be simply referred to the scaling pattern of far more small things than large ones. The classification is done through dividing things into large (or called the head) and small (or called the tail) things around the arithmetic mean or average, and then recursively going on for the division process for the large things or the head until the notion of far more small things than large ones is no longer valid, or with more or less similar things left only.[1]
Motivation
The head/tail breaks is mainly motivated by inability of conventional classification methods such as equal intervals, quantiles, geometric progressions, standard deviation, and natural breaks - commonly known as Jenks natural breaks optimization for revealing the underlying scaling pattern of far more small things than large ones. Note that the notion of far more small things than large one is not only referred to geometric property, but also to topological and semantic properties. In this connection, the notion should be interpreted as far more unpopular (or less-connected) things than popular (or well-connected) ones, or far more meaningless things than meaningful ones.
Method
Given some variable X that demonstrates a heavy-tailed distribution, there are far more small x than large ones. Take the average of all xi, and obtain the first mean m1. Then calculate the second mean for those xi greater than m1, and obtain m2. In the same recursive way, we can get m3 depending on whether the ending condition of no longer far more small x than large ones is met. For simplicity, we assume there are three means, m1, m2, and m3. This classification leads to four classes: [minimum, m1], (m1, m2], (m2, m3], (m3, maximum]. In general, it can be represented as a recursive function as follows:
Recursive function Head/tail Breaks:
Break the input data (around mean or average) into the head and the tail;
// the head for data values greater the mean
// the tail for data values less the mean
while (head <= 40%):
Head/tail Breaks(head);
End Function
The resulting number of classes is referred to as ht-index, an alternative index to fractal dimension for characterizing complexity of fractals or geographic features: the higher the ht-index, the more complex the fractals.[2] Recently, a more sensitive ht-index, namely CRG-index,[3] has been developed, and it is able to capture slight changes which ht-index is unable to. Thus while ht-index is an integer, CRG-index is a real number. A PostgreSQL function for calculating ht-index can be found here.[4]
Threshold or its sensitivity
The criterion to stop the iterative classification process using the head/tail breaks method is that the remaining data (i.e., the head part) are not heavy-tailed, or simply, the head part is no longer a minority (i.e., the proportion of the head part is no longer less than a threshold such as 40%). This threshold is suggested to be 40% by Jiang et al. (2013),[5] just as the codes above (i.e., head <= 40%). But sometimes a larger threshold, for example 50% or more, can be used, as Jiang and Yin (2014)[2] noted in another article: "this condition can be relaxed for many geographic features, such as 50 percent or even more". However, all heads' percentage on average must be smaller than 40% (or 41, 42%), indicating far more small things than large ones. This sensitivity issue deserves further research in the future.
Applications
Instead of more or less similar things, there are far more small things than large ones surrounding us. Given the ubiquity of the scaling pattern, head/tail breaks is found to be of use to statistical mapping, map generalization, cognitive mapping and even perception of beauty .[5][6][7] It helps visualize big data, since big data are likely to show the scaling property of far more small things than large ones. The visualization strategy is to recursively drop out the tail parts until the head parts are clear or visible enough. [8] In addition, it helps delineate cities or natural cities to be more precise from various geographic information such as street networks, social media geolocation data, and nighttime images.
Characterizing the imbalance
As the head/tail breaks method can be used iteratively to obtain head parts of a data set, this method actually captures the underlying hierarchy of the data set. For example, if we divide the array (19, 8, 7, 6, 2, 1, 1, 1, 0) with the head/tail breaks method, we can get two head parts, i.e., the first head part (19, 8, 7, 6) and the second head part (19). These two head parts as well as the original array form a three-level hierarchy:
the 1st level (19),
the 2nd level (19, 8, 7, 6), and
the 3rd level (19, 8, 7, 6, 2, 1, 1, 1, 0).
The number of levels of the above-mentioned hierarchy is actually a characterization of the imbalance of the example array, and this number of levels has been termed as the ht-index.[2] With the ht-index, we are able to compare degrees of imbalance of two data sets. For example, the ht-index of the example array (19, 8, 7, 6, 2, 1, 1, 1, 0) is 3, and the ht-index of another array (19, 8, 8, 8, 8, 8, 8, 8, 8) is 2. Therefore, the degree of imbalance of the former array is higher than that of the latter array.
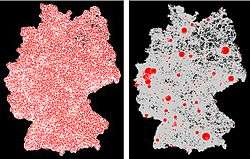
Delineating natural cities
The term ‘natural cities’ refers to the human settlements or human activities in general on Earth’s surface that are naturally or objectively defined and delineated from massive geographic information based on head/tail division rule, a non-recursive form of head/tail breaks. [9][10] Such geographic information could be from various sources, such as massive street junctions [10] and street ends, a massive number of street blocks, nighttime imagery and social media users’ locations etc. Distinctive from conventional cities, the adjective ‘natural’ could be explained not only by the sources of natural cities, but also by the approach to derive them. Natural cities are derived from a meaningful cutoff averaged from a massive amount of units extracted from geographic information. [8] Those units vary according to different kinds of geographic information, for example the units could be area units for the street blocks and pixel values for the nighttime images. A natural cities model has been created using ArcGIS model builder, [11] it follows the same process of deriving natural cities from location-based social media, [9] namely, building up huge triangular irregular network (TIN) based on the point features (street nodes in this case) and regarding the triangles which are smaller than a mean value as the natural cities.
Software implementations
The following implementations are available under Free/Open Source Software licenses.
- Ht-index calculator: a winform application for obtaining related metrics of head/tail breaks applying on a single data array.
- HT in JavaScript: a JavaScript implementation for applying head/tail breaks on a single data array.
- HT Mapping tool: a function in the free plug-in Axwoman 6.3 to ArcMap 10.2 that conducts geo-data symbolization automatically based on the head/tail breaks classification.
References
- ↑ Jiang, Bin (2013a). "Head/tail breaks: A new classification scheme for data with a heavy-tailed distribution", The Professional Geographer, 65 (3), 482 – 494.
- 1 2 3 Jiang, Bin and Yin Junjun (2014). "Ht-index for quantifying the fractal or scaling structure of geographic features", Annals of the Association of American Geographers, 104(3), 530–541.
- ↑ Gao, Peichao; Liu, Zhao; Xie, Meihui; Tian, Kun; Liu, Gang (2015-12-09). "CRG Index: A more sensitive ht-index for enabling dynamic views of geographic features". The Professional Geographer. 0 (0): 1–13. doi:10.1080/00330124.2015.1099448. ISSN 0033-0124.
- ↑ Kun Tian, Peichao Gao (2015-01-01). "A PostgreSQL function for calculating the ht-index". doi:10.13140/RG.2.1.3041.0324.
- 1 2 Jiang, Bin, Liu, Xintao and Jia, Tao (2013). "Scaling of geographic space as a universal rule for map generalization", Annals of the Association of American Geographers, 103(4), 844 – 855.
- ↑ Jiang, Bin (2013b). "The image of the city out of the underlying scaling of city artifacts or locations", Annals of the Association of American Geographers, 103(6), 1552-1566.
- ↑ Jiang, Bin and Sui, Daniel (2014). "A new kind of beauty out of the underlying scaling of geographic space", The Professional Geographer, 66(4), 676–686
- 1 2 Jiang, Bin (2015). "Head/tail breaks for visualization of city structure and dynamics", Cities, 43, 69 - 77.
- 1 2 Jiang, Bin and Miao, Yufan (2015). "The evolution of natural cities from the perspective of location-based social media", The Professional Geographer, 67(2), 295 - 306.
- 1 2 Long, Ying (2016). "Redefining Chinese city system with emerging new data", Applied Geography, 75, 36 - 48.
- ↑ Ren, Zheng (2016). "Natural cities model in ArcGIS", http://www.arcgis.com/home/item.html?id=47b1d6fdd1984a6fae916af389cdc57d.
Further reading
- Lin, Yue (2013), A comparison study on natural and head/tail breaks involving digital elevation models. http://www.diva-portal.org/smash/get/diva2:658963/FULLTEXT02.pdf
- Wu, Jou-Hsuan (2014), The mirror of the self test: http://sharon19891101.wix.com/mirror-of-the-self