Markov decision process
Markov decision processes (MDPs) provide a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying a wide range of optimization problems solved via dynamic programming and reinforcement learning. MDPs were known at least as early as the 1950s (cf. Bellman 1957). A core body of research on Markov decision processes resulted from Ronald A. Howard's book published in 1960, Dynamic Programming and Markov Processes.[1] They are used in a wide area of disciplines, including robotics, automated control, economics, and manufacturing.
More precisely, a Markov Decision Process is a discrete time stochastic control process. At each time step, the process is in some state , and the decision maker may choose any action that is available in state . The process responds at the next time step by randomly moving into a new state , and giving the decision maker a corresponding reward .




The probability that the process moves into its new state is influenced by the chosen action. Specifically, it is given by the state transition function . Thus, the next state depends on the current state and the decision maker's action . But given and , it is conditionally independent of all previous states and actions; in other words, the state transitions of an MDP process satisfies the Markov property.

Markov decision processes are an extension of Markov chains; the difference is the addition of actions (allowing choice) and rewards (giving motivation). Conversely, if only one action exists for each state (e.g. "wait") and all rewards are the same (e.g. "zero"), a Markov decision process reduces to a Markov chain.
Definition
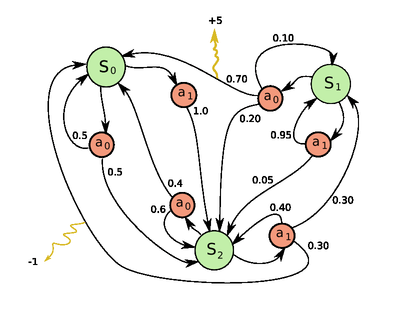
A Markov decision process is a 5-tuple , where

- is a finite set of states,
- is a finite set of actions (alternatively, is the finite set of actions available from state ),
- is the probability that action in state at time will lead to state at time ,
- is the immediate reward (or expected immediate reward) received after transitioning from state to state , due to action
- is the discount factor, which represents the difference in importance between future rewards and present rewards.






![\gamma \in [0,1]](../I/m/cbc65bc4fa0e25a8305259b234865def64ac1a8a.svg)
(Note: The theory of Markov decision processes does not state that or are finite, but the basic algorithms below assume that they are finite.)
Problem
The core problem of MDPs is to find a "policy" for the decision maker: a function that specifies the action that the decision maker will choose when in state . Note that once a Markov decision process is combined with a policy in this way, this fixes the action for each state and the resulting combination behaves like a Markov chain.


The goal is to choose a policy that will maximize some cumulative function of the random rewards, typically the expected discounted sum over a potentially infinite horizon:
- (where we choose )


where is the discount factor and satisfies . (For example, when the discount rate is r.) is typically close to 1.




Because of the Markov property, the optimal policy for this particular problem can indeed be written as a function of only, as assumed above.
Algorithms
MDPs can be solved by linear programming or dynamic programming. In what follows we present the latter approach.
Suppose we know the state transition function and the reward function , and we wish to calculate the policy that maximizes the expected discounted reward.


The standard family of algorithms to calculate this optimal policy requires storage for two arrays indexed by state: value , which contains real values, and policy which contains actions. At the end of the algorithm, will contain the solution and will contain the discounted sum of the rewards to be earned (on average) by following that solution from state .


The algorithm has the following two kinds of steps, which are repeated in some order for all the states until no further changes take place. They are defined recursively as follows:


Their order depends on the variant of the algorithm; one can also do them for all states at once or state by state, and more often to some states than others. As long as no state is permanently excluded from either of the steps, the algorithm will eventually arrive at the correct solution.
Notable variants
Value iteration
In value iteration (Bellman 1957), which is also called backward induction, the function is not used; instead, the value of is calculated within whenever it is needed. Lloyd Shapley's 1953 paper on stochastic games[2] included as a special case the value iteration method for MDPs, but this was recognized only later on.[3]
Substituting the calculation of into the calculation of gives the combined step:

where is the iteration number. Value iteration starts at and as a guess of the value function. It then iterates, repeatedly computing for all states , until converges with the left-hand side equal to the right-hand side (which is the "Bellman equation" for this problem).




Policy iteration
In policy iteration (Howard 1960), step one is performed once, and then step two is repeated until it converges. Then step one is again performed once and so on.
Instead of repeating step two to convergence, it may be formulated and solved as a set of linear equations.
This variant has the advantage that there is a definite stopping condition: when the array does not change in the course of applying step 1 to all states, the algorithm is completed.
Modified policy iteration
In modified policy iteration (van Nunen 1976; Puterman & Shin 1978), step one is performed once, and then step two is repeated several times. Then step one is again performed once and so on.
Prioritized sweeping
In this variant, the steps are preferentially applied to states which are in some way important - whether based on the algorithm (there were large changes in or around those states recently) or based on use (those states are near the starting state, or otherwise of interest to the person or program using the algorithm).
Extensions and generalizations
A Markov decision process is a stochastic game with only one player.
Partial observability
The solution above assumes that the state is known when action is to be taken; otherwise cannot be calculated. When this assumption is not true, the problem is called a partially observable Markov decision process or POMDP.
A major advance in this area was provided by Burnetas and Katehakis in "Optimal adaptive policies for Markov decision processes".[4] In this work a class of adaptive policies that possess uniformly maximum convergence rate properties for the total expected finite horizon reward, were constructed under the assumptions of finite state-action spaces and irreducibility of the transition law. These policies prescribe that the choice of actions, at each state and time period, should be based on indices that are inflations of the right-hand side of the estimated average reward optimality equations.
Reinforcement learning
If the probabilities or rewards are unknown, the problem is one of reinforcement learning (Sutton & Barto 1998).
For this purpose it is useful to define a further function, which corresponds to taking the action and then continuing optimally (or according to whatever policy one currently has):

While this function is also unknown, experience during learning is based on pairs (together with the outcome ; that is, "I was in state and I tried doing and happened"). Thus, one has an array and uses experience to update it directly. This is known as Q‑learning.


Reinforcement learning can solve Markov decision processes without explicit specification of the transition probabilities; the values of the transition probabilities are needed in value and policy iteration. In reinforcement learning, instead of explicit specification of the transition probabilities, the transition probabilities are accessed through a simulator that is typically restarted many times from a uniformly random initial state. Reinforcement learning can also be combined with function approximation to address problems with a very large number of states.
Learning Automata
Another application of MDP process in machine learning theory is called learning automata. This is also one type of reinforcement learning if the environment is in stochastic manner. The first detail learning automata paper is surveyed by Narendra and Thathachar (1974), which were originally described explicitly as finite state automata.[5] Similar to reinforcement learning, learning automata algorithm also has the advantage of solving the problem when probability or rewards are unknown. The difference between learning automata and Q-learning is that they omit the memory of Q-values, but update the action probability directly to find the learning result. Learning automata is a learning scheme with a rigorous proof of convergence.[6]
In learning automata theory, a stochastic automaton to consist of:
- a set x of possible inputs,
- a set Φ = { Φ1, ..., Φs } of possible internal states,
- a set α = { α1, ..., αr } of possible outputs, or actions, with r≤s,
- an initial state probability vector p(0) = ≪ p1(0), ..., ps(0) ≫,
- a computable function A which after each time step t generates p(t+1) from p(t), the current input, and the current state, and
- a function G: Φ → α which generates the output at each time step.
The states of such an automaton correspond to the states of a "discrete-state discrete-parameter Markov process".[7] At each time step t=0,1,2,3,..., the automaton reads an input from its environment, updates P(t) to P(t+1) by A, randomly chooses a successor state according to the probabilities P(t+1) and outputs the corresponding action. The automaton's environment, in turn, reads the action and sends the next input to the automaton.[6]
Category theoretic interpretation
Other than the rewards, a Markov decision process can be understood in terms of Category theory. Namely, let denote the free monoid with generating set A. Let Dist denote the Kleisli category of the Giry monad. Then a functor encodes both the set S of states and the probability function P.



In this way, Markov decision processes could be generalized from monoids (categories with one object) to arbitrary categories. One can call the result a context-dependent Markov decision process, because moving from one object to another in changes the set of available actions and the set of possible states.


Fuzzy Markov decision processes (FDMPs)
In the MDPs, optimal policy is a policy which maximize the summation of future rewards. Therefore, optimal policy consist several actions which belong to a finite set of actions. In Fuzzy Markov decision processes (FDMPs), first, the value function is computed as regular MDPs i.e. with a finite set of actions; then, the policy is extracted by a fuzzy inference system. In other words, the value function is utilized as an input for the fuzzy inference system, and the policy is the output of the fuzzy inference system. [8]
Continuous-time Markov Decision Process
In discrete-time Markov Decision Processes, decisions are made at discrete time intervals. However, for Continuous-time Markov Decision Processes, decisions can be made at any time the decision maker chooses. In comparison to discrete-time Markov Decision Process, Continuous-time Markov Decision Process can better model the decision making process for a system that has continuous dynamics, i.e., the system dynamics is defined by partial differential equations (PDEs).
Definition
In order to discuss the continuous-time Markov Decision Process, we introduce two sets of notations:
If the state space and action space are finite,
- : State space;
- : Action space;
- : , transition rate function;
- : , a reward function.





If the state space and action space are continuous,
- : state space;
- : space of possible control;
- : , a transition rate function;
- : , a reward rate function such that , where is the reward function we discussed in previous case.








Problem
Like the Discrete-time Markov Decision Processes, in Continuous-time Markov Decision Process we want to find the optimal policy or control which could give us the optimal expected integrated reward:
![{\displaystyle \max \quad \mathbb {E} _{u}[\int _{0}^{\infty }\gamma ^{t}r(x(t),u(t)))dt|x_{0}]}](../I/m/9fc785415cd01e384ee32909eefcfa9a68ce9150.svg)
Where

Linear programming formulation
If the state space and action space are finite, we could use linear programming to find the optimal policy, which was one of the earliest approaches applied. Here we only consider the ergodic model, which means our continuous-time MDP becomes an ergodic continuous-time Markov Chain under a stationary policy. Under this assumption, although the decision maker can make a decision at any time at the current state, he could not benefit more by taking more than one action. It is better for him to take an action only at the time when system is transitioning from the current state to another state. Under some conditions,(for detail check Corollary 3.14 of Continuous-Time Markov Decision Processes), if our optimal value function is independent of state , we will have the following inequality:


If there exists a function , then will be the smallest satisfying the above equation. In order to find , we could use the following linear programming model:



- Primal linear program(P-LP)

- Dual linear program(D-LP)

is a feasible solution to the D-LP if is nonnative and satisfied the constraints in the D-LP problem. A feasible solution to the D-LP is said to be an optimal solution if



for all feasible solution to the D-LP. Once we found the optimal solution , we could use those optimal solution to establish the optimal policies.
Hamilton-Jacobi-Bellman equation
In continuous-time MDP, if the state space and action space are continuous, the optimal criterion could be found by solving Hamilton-Jacobi-Bellman (HJB) partial differential equation. In order to discuss the HJB equation, we need to reformulate our problem
![\begin{align} V(x(0),0)=&\text{max}_u\int_0^T r(x(t),u(t))dt+D[x(T)]\\
s.t.\quad & \frac{dx(t)}{dt}=f[t,x(t),u(t)]
\end{align}](../I/m/e1f5d186c0160ec17542d71e05900d8bab9ea0e8.svg)
is the terminal reward function, is the system state vector, is the system control vector we try to find. shows how the state vector change over time. Hamilton-Jacobi-Bellman equation is as follows:





We could solve the equation to find the optimal control , which could give us the optimal value
Application
Continuous-time Markov decision processes have applications in queueing systems, epidemic processes, and population processes.
Alternative notations
The terminology and notation for MDPs are not entirely settled. There are two main streams — one focuses on maximization problems from contexts like economics, using the terms action, reward, value, and calling the discount factor or , while the other focuses on minimization problems from engineering and navigation, using the terms control, cost, cost-to-go, and calling the discount factor . In addition, the notation for the transition probability varies.


| in this article | alternative | comment |
|---|---|---|
| action | control | |
| reward | cost | is the negative of |
| value | cost-to-go | is the negative of |
| policy | policy | |
| discounting factor | discounting factor | |
| transition probability | transition probability |




In addition, transition probability is sometimes written , or, rarely,



Constrained Markov Decision Processes
Constrained Markov Decision Processes (CMDPs) are extensions to Markov Decision Process (MDPs). There are three fundamental differences between MDPs and CMDPs.[9]
- There are multiple costs incurred after applying an action instead of one.
- CMDPs are solved with Linear Programs only, and Dynamic programming does not work.
- The final policy depends on the starting state.
There are a number of applications for CMDPs. It is recently being used in motion planning scenarios in robotics.[10]
See also
- Probabilistic automata
- Quantum finite automata
- Partially observable Markov decision process
- Dynamic programming
- Bellman equation for applications to economics.
- Hamilton–Jacobi–Bellman equation
- Optimal control
- Recursive economics
- Mabinogion sheep problem
- Stochastic games
- Q-learning
Notes
- ↑ Howard 1960.
- ↑ Shapley 1953.
- ↑ Kallenberg 2002.
- ↑ Burnetas & Katehakis 1997.
- ↑ Narendra & Thathachar 1974.
- 1 2 Narendra & Thathachar 1989.
- ↑ Narendra & Thathachar 1974, p.325 left.
- ↑ Fakoor, Mahdi; Kosari, Amirreza; Jafarzadeh, Mohsen (2016). "Humanoid robot path planning with fuzzy Markov decision processes". Journal of Applied Research and Technology. doi:10.1016/j.jart.2016.06.006.
- ↑ Altman 1999.
- ↑ Feyzabadi & Carpin 2014.
References
- Altman, Eitan (1999). Constrained Markov decision processes. 7. CRC Press.
- Bellman, R. (1957). "A Markovian Decision Process". Journal of Mathematics and Mechanics. 6.
- Bellman., R. E. (2003) [1957]. Dynamic Programming (Dover paperback ed.). Princeton, NJ: Princeton University Press. ISBN 0-486-42809-5.
- Bertsekas, D. (1995). Dynamic Programming and Optimal Control. 2. MA: Athena.
- Burnetas, A.N.; Katehakis, M. N. (1997). "Optimal Adaptive Policies for Markov Decision Processes". Mathematics of Operations Research. 22 (1): 222. doi:10.1287/moor.22.1.222.
- Derman, C. (1970). Finite state Markovian decision processes. Academic Press.
- Feinberg, E.A.; Shwartz, A., eds. (2002). Handbook of Markov Decision Processes. Boston, MA: Kluwer.
- Feyzabadi, S.; Carpin, S. (18–22 Aug 2014). "Risk-aware path planning using hierarchical constrained Markov Decision Processes". Automation Science and Engineering (CASE). IEEE International Conference. pp. 297,303.
- Guo, X.; Hernández-Lerma, O. (2009). Continuous-Time Markov Decision Processes. Springer.
- Howard, Ronald A. (1960). Dynamic Programming and Markov Processes (PDF). The M.I.T. Press.
- Kallenberg, Lodewijk (2002). "Finite state and action MDPs". In Feinberg, Eugene A.; Shwartz, Adam. Handbook of Markov decision processes: methods and applications. Springer. ISBN 0-7923-7459-2.
- Meyn, S. P. (2007). Control Techniques for Complex Networks. Cambridge University Press. ISBN 978-0-521-88441-9. Archived from the original on 19 Jun 2010. Appendix contains abridged "Meyn & Tweedie". Archived from the original on 18 Dec 2012.
- Narendra, K. S.; Thathachar, M. A. L. (1974-07-01). "Learning Automata - A Survey". IEEE Transactions on Systems, Man, and Cybernetics. SMC-4 (4): 323–334. doi:10.1109/TSMC.1974.5408453. ISSN 0018-9472.
- Narendra, Kumpati S.; Thathachar, Mandayam A. L. (1989). Learning automata: An introduction. Prentice Hall. ISBN 9780134855585.
- Puterman, M. L.; Shin, M. C. (1978). "Modified Policy Iteration Algorithms for Discounted Markov Decision Problems". Management Science. 24.
- Puterman., M. L. (1994). Markov Decision Processes. Wiley.
- Ross, S. M. (1983). Introduction to stochastic dynamic programming. Academic press.
- Shapley, Lloyd (1953). "Stochastic Games". Proceedings of National Academy of Science. 39: 1095–1100.
- Sutton, R. S.; Barto, A. G. (1998). Reinforcement Learning: An Introduction. Cambridge, MA: The MIT Press.
- Tijms., H.C. (2003). A First Course in Stochastic Models. Wiley.
- van Nunen, J.A. E. E (1976). "A set of successive approximation methods for discounted Markovian decision problems. Z". Operations Research. 20: 203–208.
External links
- MDP Toolbox for MATLAB, GNU Octave, Scilab and R The Markov Decision Processes (MDP) Toolbox.
- MDP Toolbox for Matlab - An excellent tutorial and Matlab toolbox for working with MDPs.
- MDP Toolbox for Python A package for solving MDPs
- Reinforcement Learning An Introduction by Richard S. Sutton and Andrew G. Barto
- SPUDD A structured MDP solver for download by Jesse Hoey
- Learning to Solve Markovian Decision Processes by Satinder P. Singh
- Optimal Adaptive Policies for Markov Decision Processes by Burnetas and Katehakis (1997).